 HashMap扩容的rehash
HashMap扩容的rehash
# HashMap扩容的rehash
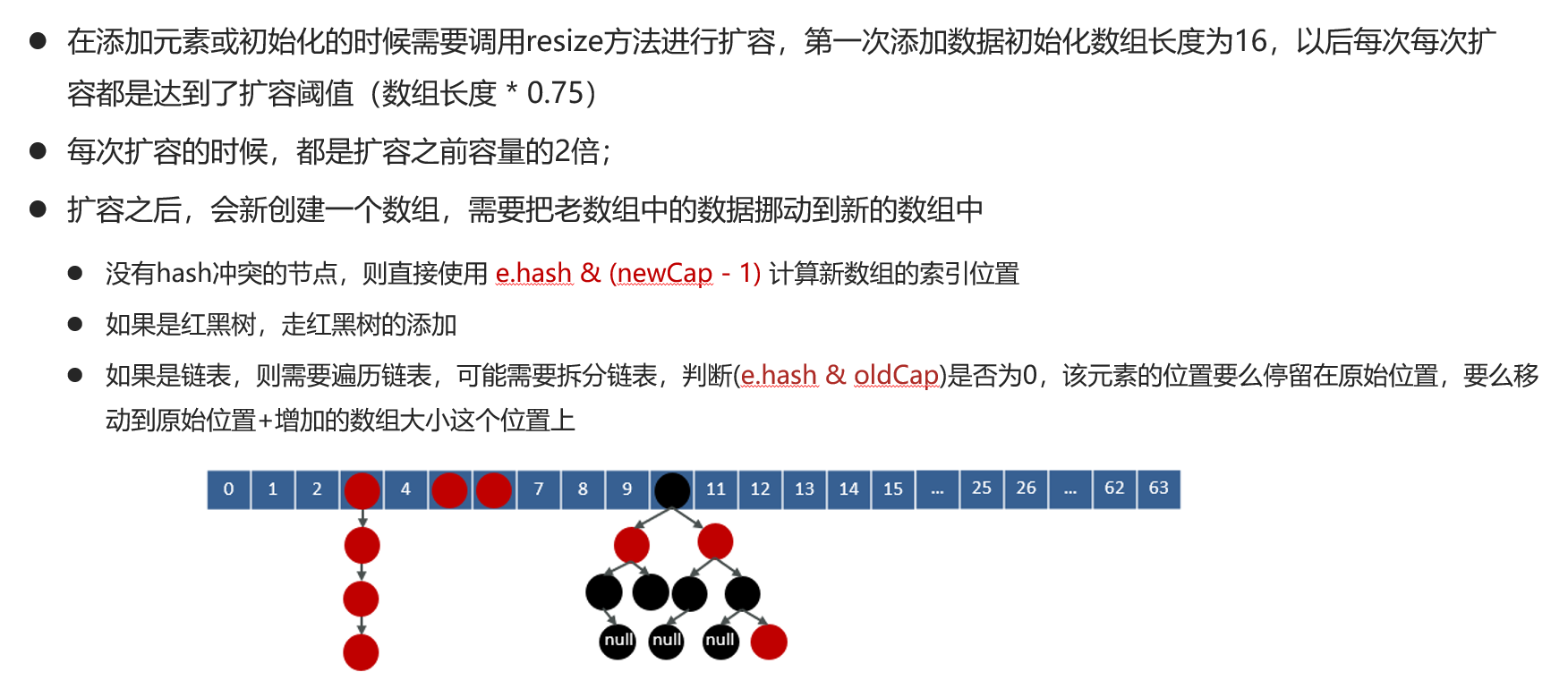
首先申明一点,重新rehash的节点最终的位置只有两个,一个是继续在原数组的位置,另一个是原数组的索引加上原数组的大小的位置上,
对于没有发生冲突的节点:节点key的hash值与新的数组长度减一进行与运算得到新的数组下标
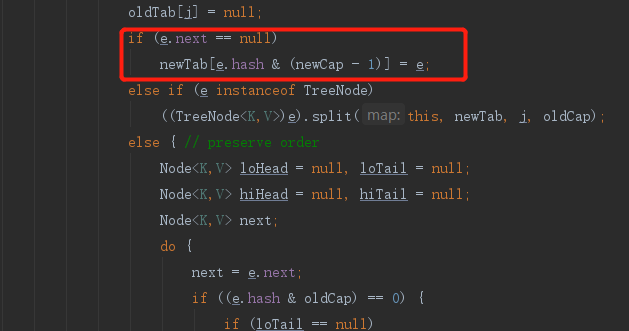
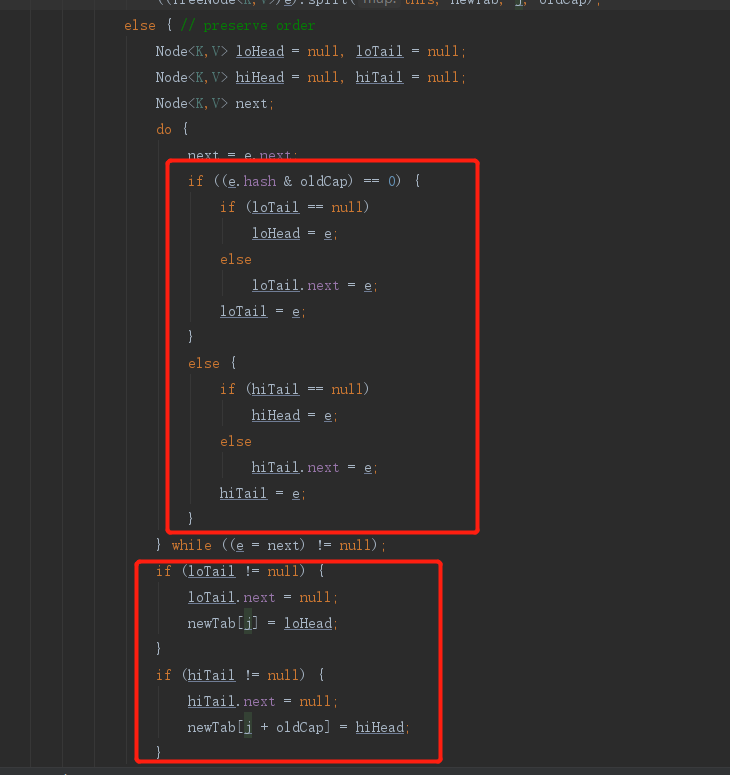
对于链表节点:我们之前说过rehash的节点最终的位置只有两个,一个是继续在原数组索引的位置,另一个是原数组的索引加上原数组的大小的位置上,所以对于链表节点会遍历整个连败哦,最后形成两个链表,一个会在原数组索引的位置,另一个会在原数组的索引加上原数组的大小的位置上,区分两个链表的条件是判断 e.hash & oldCap是否为0 ,为0的元素组成一个链表,不为0的组成一个链表。最后挂载到指定位置。
对于红黑树节点与链表同理,只不过最后会判断一下新的红黑树是否要变成树
单个节点
其实重新进行hash寻址算法,找到对应数组的下标,放上就行了
2)链表
仔细阅读源码会发现,就是将之前的链表rehash之后重新拆分为了两个链表,一个链表rehash之后还是在当前的位置index,另一个链表rehash之后的位置变成了index + oldCap,画个图理解一下
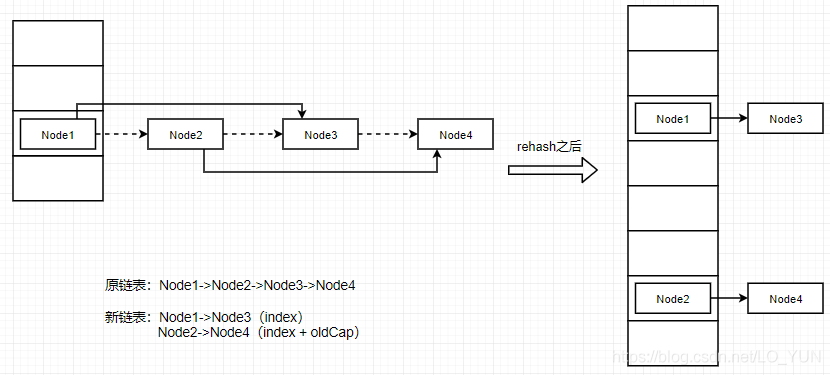
至于为什么可以分为两个链表,这里说明一下。就是hash寻址算法对一个数组下标的所有节点,扩容后进行重新计算的时候,会发现计算出来的位置要么是在原来的index,要么实在原来的index + oldCap的位置,这是hash寻址的一个特点,所以基于这一个既定的结论,就去判断一下每个节点重新hash寻址之后是原来的位置还是index + oldCap的位置就行了(如何判断,就是源码图的第一个红框框出来的),判断是在原来的位置然后一个新的链表,在index + oldCap的位置也形成一个新的链表,这样计算完之后只要把新的两个链表挂在新的数组的 index 和 index + oldCap就行了(如何挂的,就是源码图的第二个红框框出来的,也就是j与j + oldCap两个位置)。这样就避免了对每个节点重新进行hash寻址算法,重新放到hash表中的过程,大大提高了效率,这也就是JDK1.8的HashMap扩容rehash算法优化。
3)红黑树
贴上源码
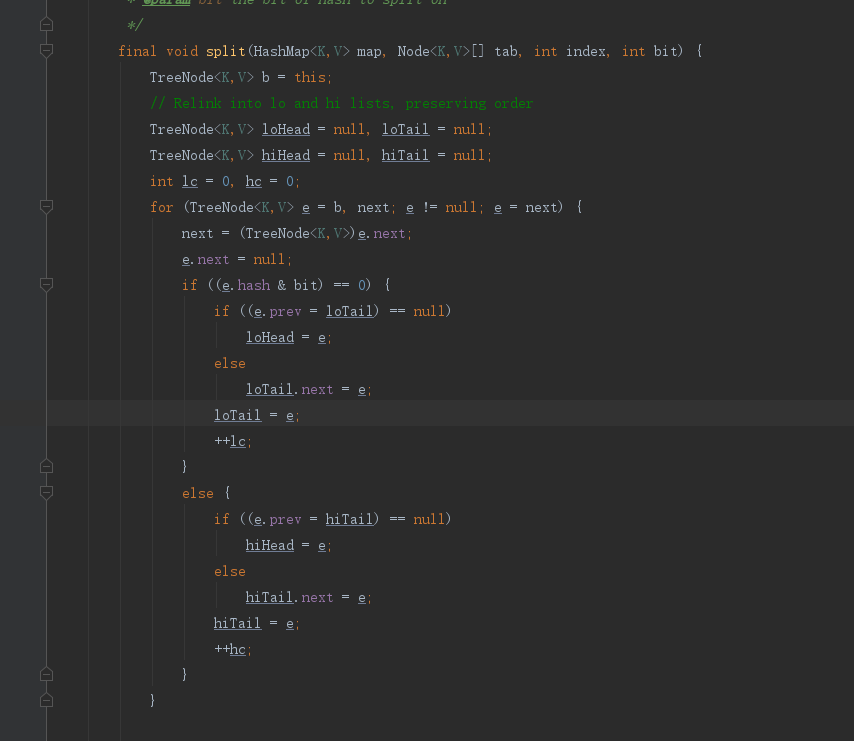
其实原理跟链表的差不多,就是链表拆成两个链表,红黑树这个拆成两个红黑树,分别挂到新的数组的位置上,只不过最后加个判断,就是判断这个红黑树是需要变成链表还是继续是红黑树。
所以在JDK1.8的rehash算法优化就是对原来的链表或者红黑树进行拆分成两部分,然后分别挂在原来数组的位置和 数组的位置 + oldCap的位置,这样做就避免了大量的节点进行重新hash寻址算法和重新放到hash表的过程,大大增加了扩容效率。